Building my Website from Scratch
12/20/2022I’m going to shake things up a little. This post will be a technical overview of the website I recently built from scratch and deployed at spenpo.com. My blog will still come back to introspection, but its purpose has always been to explain the things I do. Creating content is an attempt at teaching. It’s a way to summarize an understanding you’ve gained. It’s been said that you don’t know very much about a topic until you start teaching it to others. Assuming this is true, writing about the thing you want to become an expert at is a great way to hone your craft. Well, there are many crafts I wish to hone, and though deep thought and self-reflection are paramount to all crafts, the thinker should also be a builder. Walking this fine line between thought and craft makes me think two separate blogs might be warranted. But for now, this will do.
Overview
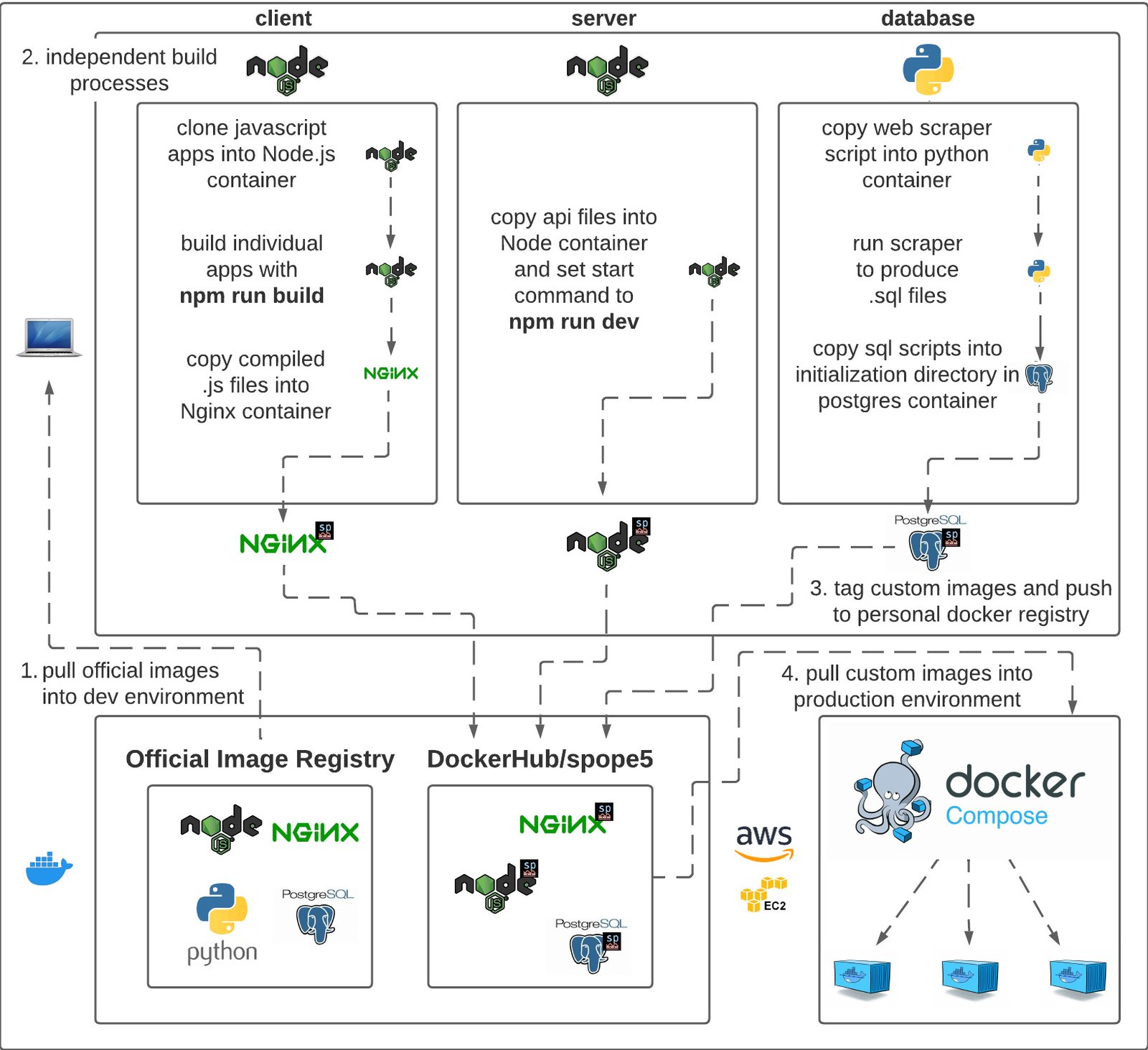
The site’s frontend is static html that also includes several framework-based features that are integrated during the build process. The backend is a simple Express.js API that can be used to supplement any features needing outside data, of which there are currently four. The database is PostgreSQL. These three main services all have separate build processes that produce a docker image, and docker compose is used to deploy each image to a container and run them together on my production server. All the infrastructure is in AWS. The server is an EC2 t2.nano instance, which is the smallest instance Amazon offers. If you choose to run Amazon Linux 2, (AWS’s in-house Linux distribution), it is also the cheapest option at $0.0058 per hour. Running this site will cost about $51 per year. This post will also be a deep dive into the four pillars of the site I’ve mentioned so far: frontend, backend, storage, and infrastructure.
Frontend
The site is currently only three static pages. There’s a homepage, projects, and resume. The homepage is made up of four features, two of which are React components. There’s a box labeled ‘check out my latest post’, another labeled ‘see what else I’m working on’, one labeled ‘send me an email’, and all the way to the right is my twitter feed. The first one has a link preview below the heading which will open my latest blog post in a new tab when clicked. This is a small react component that I built myself. A link preview is like a hyperlink that shows the user some additional information to make clicking there more attractive. They commonly display an image, title, and description of the link, so I knew something like that would be a better user of web real estate than a skinny blue hyperlink in the middle of my site. I was surprised to find out that the link preview, though an increasingly universal concept, is a commonly centralized web feature in organizations. This means that Twitter has their own link preview that they display for you when they find a hyperlink in your posts. Facebook, Medium, and other social media companies probably have the same type of thing, and comb through their users’ posts to render their shinny link preview component. This article explains how their components are likely quite advanced, using a web scraper to find open graph tags that hold the data they need for the preview. Learning this was quite tempting, but I decided not to get distracted by the lure of having my very own link preview api like the companies I’ve mentioned. The next option was to go open source, but I was disappointed with the flexibility of most link preview components I found on npm. I found that all I really wanted was a dumb component that looked the way I wanted and displayed the info I wanted. When I realized I could probably build that from one row of data and less than a hundred lines of React code, I just started. The thing is just one .jsx file that calls one of my endpoints to get the data it needs and renders them in the HTML elements I setup. The data is in my site’s Postgres container, so if I want to update the link, I don’t even have to redeploy the site, I just log into the server and run an insert query in psql. This gave me all the control and customization I wanted for a fun little half-day side quest.
The Twitter feed works the exact same way. It’s another single file React component that just calls the Twitter api with my username and renders my tweets in the exact format I want them. This isn’t to say that the open-source route wasn’t an option again. In fact, there’s a marvelous library with a React Timeline component that I’ve used in past projects. Projects like that are great, but I took this as an opportunity to fiddle with the Twitter api on my own and build something I knew I was capable of in order to avoid another dependency. And if you’re wondering, the other two pages on my site work similarly. The resume page is nothing but a React app. The projects page is setup with a table format and uses JavaScript to display apps based on the user’s selection. There are Svelte apps in there too! I’ll go over that in another post. So, I built two little React apps for my site. Now, how do I get them in there?
I found that loading react directly in the HTML like they describe here was the easiest way to add them in, but ultimately bloated my codebase and slowed down the site. This is because it’s loading a compiler, which is a complex piece of software that translates React into something the browser knows what to do with. JSX is compiled by babel, which takes a combination of JavaScript, HTML, and CSS code and compiles it into a few JavaScript files and one CSS file. This is what happens when you run npm run build. If you bootstrapped your app with create-react-app, it uses the react-scripts module to invoke babel on your project and compile it down to those production ready files. Since I only wanted to include small React features in my primarily static site, all I needed were those couple files from babel. React works by rendering elements to one specific element that you tell React-Dom to look for, so as long as that element is on the page and I’m importing the production files, voila, my component gets mounted. There are plenty of ways to stage this for rapid development, but I needed to come up with a way to do all this crazy compiling beforehand so that my server only needs to look at a couple HTML and JavaScript files. Remember, the site’s running on a virtual machine (VM) with half a gig of memory.
Docker solves all of this. I mentioned that my site’s three services all have independent build processes. These are all configured by a Dockerfile at the root of their respective directories. The Dockerfile for my client-side service can be found here. This is a multistage build process that compiles all the different JavaScript framework-based features in my site and integrates them with the static html codebase I’ve setup. By ‘integrates,’ all I mean is that it takes those compiled files we talked about and puts them in a directory that my static site is ready to import them from. Hosting a site on the web requires a web server, so I chose to use the official Nginx Docker image as mine. The image is a virtual machine that has Nginx properly installed and ready to serve some code to its visitors. All you have to do is put the code you want it to serve in the right place, so that Nginx can find it when someone’s browser asks for it. Docker makes this easy with its lovely COPY command. On line 6 of the Dockerfile I copy “.” (all the files and directories in the same location as the Dockerfile), from my computer into the following directory inside the Docker container: /etc/nginx/html. That means when the container is running, Nginx will be able to see my index.html file for my homepage and my /projects and /resume directories, so it will have everything it needs to serve my static content. Now, we’ve still got to get those JavaScript files in there.
This is where multi-stage builds come in handy. I already said that all we need to run the site is a web server, so we’re using Nginx for that. But in order to build the site, we need different software. Well, the point of Docker is not having to run a bunch of crazy software that might not play nice together. If I need Node.js to build my React apps, but I don’t want to be bugging Nginx in production, Docker makes it so I don’t have to mix my chocolate with my peanut butter. I can start a separate VM in the same Dockerfile and do all that compilation independent of my web server. You can see on line 1 of the Dockerfile that I use the FROM command to start a container with the official Node.js Docker image, and directly after that I name the build stage ‘builder’. Doing so allows me to start a new build stage from the image that comes out of the builder stage in the future. The only thing I do to the Node image in the first stage is install git on line 2. That means everywhere else in this Dockerfile where I start a stage with FROM builder, I am starting with a fresh Node image that has git installed. As you can see, the rest of the stages all involve the same pattern of starting from the builder image, cloning a repository with my React code in it, installing the app’s dependencies with npm i, compiling the code with npm run build, and copying all the compiled code into the container. Then, the build stages that use my web server image copy only the compiled production files from the builder container into the directory my html files will be trying to import them from in the Nginx container. For example, this file is expecting to find a file called main.js in the following location relative to its root: /react-apps/home/js/main.js. It will be looking for the file from inside the Nginx container, which is why the hraServer stage, (home react apps), copies the production files from the /build/static directory in the hraBuilder Node container into the following directory inside of Nginx: /etc/nginx/html/react-apps/home/. Each build stage is setup with this pattern so that all of my framework-based features are compiled inside a clean Node VM and then the necessary files copied to the appropriate place in my web server. This also enhances local development because it takes a good minute or two to install dependencies and build one of these apps, so if you want to test some changes on only one of them you can use the --target flag to stop building the image after a particular stage. The resulting image that comes out of this Dockerfile is a very lightweight version of Nginx with access to only the necessary client-side code properly oriented for my site.
I then tag all the images and push them up to my personal Docker registry in DockerHub, and then the only thing my server needs to know is where to find my custom image. Since my site is a multi-container application, I use Docker-compose to share this information with it. Compose allows me to start multiple docker containers with one .yml file like this. As you can see, my client service is pulling the meDotCom-client image from my personal corner of docker hub, denoted by my username. The only other trick involved in that service is using the port flag to map port 80 inside the Nginx container to port 80 in the computer running docker compose. In this case, that computer is my EC2 instance, which is configured to route traffic to the default HTTP port, which is 80. This just makes it so that going directly to my domain, (spenpo.com), routes you first to the server that is my EC2 instance, and then to the VM inside the server that is my Nginx Docker container. Configuring the instance to port 3000 instead would just mean that users must go to spenpo.com:3000 to see my site, which isn’t as convenient as the default port.
This sums up the entire client-side service. The resume page is also an HTML page with a single <div> element waiting for those JavaScript files to bind to it and render my resume react app. The projects page is mostly the same except it has some extra JavaScript here that controls which app you will see in the table depending on which tab you’ve chosen. I think this has set me up with a sustainable way to continuing to integrate more of my projects with the site without significantly bloating the codebase each time. And the build process happens almost entirely on my own laptop, so anytime I want to make changes I just tag a new image and push it to docker hub, then log into the EC2 instance and run docker-compose pull and restart the container.
Storage
I chose PostgreSQL for my site’s first database because I only needed support for a couple select queries and Postgres integrates well with Node.js. Another advantage was that the official Postgres Docker image has a nice feature where any SQL scripts it finds in a special directory will be run when the database is being initialized. The image relies on another directory at /var/lib/postgresql/data for caching the data that the user keeps in the database. If Postgres finds some data in that directory, it doesn’t bother with initialization when starting the container. Therefore, I mount a volume of that directory to my project’s root with Docker Compose. It makes it easy to test out scripts, because all you must do is remove that directory and the container will perform initialization the next time it starts. This makes adding outside data support very strait forward. I have a couple scripts in the sql directory of my project that get copied into the init.d directory of the container while my custom Postgres image is being built. One of them creates all the tables for my project. This means anytime I want to add support for new data I just add a new create table statement to that script. The three tables I create with that script right now store the data for my link preview component and the data for two of the apps on my projects page.
I’ll always know what data I want to go in the link preview when I’m getting ready to deploy the site, so I keep an insert script in that same directory that adds a row to the table my link preview is pulling from. What makes this initialization trick even more powerful however, is multi-stage builds. I built the language-flash app on my projects page because I wanted to make something that would help me learn the most common words in a new language very quickly. I found a Wikipedia page with the 1000 most common Mandarin words, and naturally used Python to scrape them into a JSON file. I’ve always used Python for gathering data from the web, it might well be the only thing I remember how to use it for at this point. The problem is I don’t want a 1000 item JSON array sitting on my production server. Once I decided I wanted to publish the app online, that data obviously had to go in a database. Well, since I already had that nice script, I just tweaked it to spit out insert statements instead of JSON objects and changed the extension of the output file to .sql. Then in my Dockerfile, I added a build stage called scraper that uses a Python image to run the script, and the only thing left to do is copy the output of the script into the Postrges image.
I was ecstatic to see how well this pieced together. I’ve done plenty of projects where the data layer rests on a manual execution of some Python scripts, but this was the first time I had to get that data production ready. Creating this process got me thinking about all sorts of cool stuff I could do with the same architecture. Last year I was building a trading app that relied on data from the NBA to track players’ stats. If I ever released that project, I would’ve needed an ETL that was running my python scripts every night and sticking whatever they found in my database. There’s so much nuance that makes this a wildly different process than scraping some data one time and sticking it into Postgres. It’s pretty fun to think through, how would you do it?
Backend
The backend is one Express.js API right now. Though it’s the simplest piece of the puzzle, it’s still a crucial tether between the client container and the database. The Node Docker image makes it easy to run your own API in a container, and Node easily connects to Postgres via the pg package. The only tricky part here is lining up all the ports so that the containers can talk to each other. Picture the Node container holding two tin cans, one to each of its ears. One of those cans is on a string where Postgres is talking into a can on the other end, and the other is on a string where Nginx is listening on the other end. I’ll start explaining at the Postgres end.
When you start a Postgres container it runs on the default port 5438. This was fine with me, so I left it that way. That’s just the internal container port though, (I know, this again). In order to get the two tin cans connected, the two containers must go through the ports of the computer they’re both running on. For this reason, I use Docker Compose to map port 5438 in the container to a port specified in the environment variables in the host shell, (my EC2 instance). Then I set the $PGPORT environment variable in the Node container to the same variable in the shell so that it can use that when connecting to Postgres. There’s a nice npm package called pg that handles the database connection once configured. All the API logic is currently in one single file called server.js. In this file I import the Pool constructor from pg and feed it all the data it needs to connect to my database. The five things it needs are user, password, host, database, and port. Docker Compose makes it easy to pass this information in from the shell it’s running on. Since the user, password, and host of the Postgres container are set via environment variables too, I set those same variables for the Node container so that I can pass them to the Pool constructor from the process.env object. The port must match the outer port that the database container is mapped to, and the host is just the name of the service running Postgres. Once that connection is established, we can query our database! New instances of the Pool constructor have a property called query. This is a function that takes a string of valid SQL code. Running the function pool.query('SELECT * FROM mandarin;') will return a promise with the result of the query in JSON format. So, if everything is properly linked, meaning the Postgres image built properly so that the data from our Python script was initialized in the database, and the correct environment variables were set so that Node can connect, then the tin-can-telephone should function as intended, and that promise will resolve to an array of the Mandarin words and their meanings that we mined from Wikipedia. Wrap those few lines of code in a good old-fashioned Express GET request, and our API is ready to go.
Now that Node can hear what Postgres has to say, it’s time to hook up Nginx’s phone line. This will be quick. If you’ve started and Express server before, you know the last order of business is to run the function app.listen() and pass in the port you want it to run on. More fun with ports! The problem is that will run on the Node container’s internal port of your choice. The solution comes through some custom configuration in our Nginx container. It’s a common maneuver to write a custom default.conf file for situations like this, and then replace the stock file that comes with the official Docker image when building a custom image. We can use the upstream directive within this file to proxy incoming requests to wherever else we want them to go. Since I’ve named the backend Node service ‘api’ I use the first three lines to tell Nginx that any requests to the api service should be sent upstream to my backend service which is running on api:5000 (hostname:port). Then below in my server rules I set up a rule for requests with the path /api. The rule says when a request matches the regex /api/(.*) it should be rewritten as a request to my upstream server with the same path as the incoming request. This means that a request to /api/foo/bar will be rewritten to http://api:5000/foo/bar. The advantage of this complicated dance is that it makes our lives easy when making requests to the backend service from the client side. Whether it’s from static HTML or a JavaScript framework, all I have to do is call my endpoint with /api in front of it to get some data from my server. This way, I won’t have to scour the app for every request if I ever decide to change where my backend is hosted. It provides a lot of extra control from a very simple, yet powerful file. This is one of the features of Nginx I’d like to learn much more about.
The tin can phone lines are all hooked up now, and my client-side apps can get data out of Postgres that will be served to them by Node. This system is flexible and can be easily customized. If I build some kind of data aggregation app, I can add a MongoDB container and integrate that with my api. The Node service already has some endpoints that make subsequent requests to elsewhere on the internet, and the beauty of it is that it will proxy my requests to anything I can add support for. This will give me the freedom I wanted to experiment with different tech stacks and showcase what I’ve built all in one place.
Infrastructure
The cloud engineering of this project has been made unadorned by courtesy of Docker Compose. This is the first site I’ve deployed to the internet on my own, and my experience configuring servers up until now has been minimal. The way I protect myself from my own inexperience in this case is by keeping most of the action off the server. The less you have to do on your server, the less likely you are to mess it up.
I used to work for a company that had its production servers in a closet somewhere in the office. Once a month we would do a product release, and I was invited to these meetings to watch in awe as our devops engineer would wipe each servers’ file system clean and proceed to reinstall Node.js to ensure a stable environment. The number of times I’ve seen Node installed on an elderly Windows box is insane. We’d perform this ritual for what usually took one hour. Other activities on the call were things like cloning projects onto the server and installing dependencies. Exciting stuff. And all this time the product was down, (we worked nights once a month to do this for the convenience of our customers). The moral of the story is that’s a whole lot of work that must be done on the production server. Even when we automated this process, we would still watch all the same commands get run in order, leaving the system fragile if we were to add a new software solution to the mix. I plan to be adding new software to my site on a regular basis, so I also want to minimize the number of chances there are to mess up my server.
By pushing the custom images I’ve already built on my local machine up to DockerHub, I can now run my entire site with one compose file. The server also doesn’t need to spend any time building my project. Sometimes those images would take five minutes a piece for my mac to build, so I don’t want that stress on my server, and I also don’t want to pay for a server with that much memory when I only really need it for the builds. Right now, my client image build process has to clone four different repositories, install their dependencies, and build all the projects individually, all just to copy a couple resulting files into the final Nginx image. Doing so eats up gigabits on my computer every time I create a new build, but then the image is only 130mb. Keeping the three images’ combined weight below 0.5gb is imperative for being able to run them on a t2.nano in AWS. I believe this is the cheapest server space there is for a project of this complexity. And complex as it may be, all it takes on a brand new EC2 instance is installing docker and docker compose to get this thing going. I took the liberty of installing git on it as well so that I can easily pull changes down when the compose file gets updated. And that one file is truly the only thing the app stands on. If I didn’t want the source files from my repository sitting on the server anymore for some reason, I could remove them. I could even remove git and use scp to copy the compose file from my laptop to the server over ssh. And t’s far from continuous integration but stopping the containers to run docker-compose pull before starting them right back up is less than a minute of downtime for site maintenance. I plan on looking into using AWS Codepipeline for automating the pipeline with a git hook. I’m not sure if it supports containerized apps, but I’m sure there’s something out there for automating docker-based pipelines.
In conclusion, this may seem like a purposely convoluted portfolio site that could easily be a single page app hosted for free on Vercel, but that’s no fun. Building this site was an excuse to learn so many new webdev tricks that I wouldn’t have found from my day job. I’ve gained great experience with AWS from using load balancers to configuring DNS in Route53. I’ve setup a software development life cycle that has plenty of room to grow into something modern and advanced. I’ve also designed a local development environment that lends a hand to the unfamiliar tech stack I chose. Half of this stuff is still crystalizing in my brain and all of it is good material for future articles. I’m glad I’ve got a project to refine, and more importantly, I’ve got somewhere on the web for my work to be shown off. I’m excited to keep building.
If this made you think, please share with a friend.
Please visit my Wordpress site to leave a comment on this post.